Mathematic 2 - Calculus 2 - Summary 1. Linear System
1.1 Linear Equations and Systems & Augmented Matrices
Linear Equation
Variables like x x x y y y z z z a 1 x 1 + a 2 x 2 + ⋯ + a n x n = b or a 1 x + a 2 y + ⋯ + a n z = b a_1x_1+a_2x_2+\dots+a_nx_n = b \quad \text{or} \quad a_1x+a_2y+\dots+a_nz = b a 1 x 1 + a 2 x 2 + ⋯ + a n x n = b or a 1 x + a 2 y + ⋯ + a n z = b
No variables multiplying each other.
Linear System and Its Solution
System of equations:
{ a 1 x 1 + a 2 x 2 + ⋯ + a n x n = b 1 a 11 x 1 + a 12 x 2 + ⋯ + a m n x n = b 2 ⋮ a m 1 x 1 + a m 2 x 2 + ⋯ + a m n x n = b m \begin{cases}
a_1x_1+a_2x_2+\dots+a_nx_n = b_1 \\
a_{11}x_1+a_{12}x_2+\dots+a_{mn}x_n = b_2 \\
\vdots \\
a_{m1}x_1+a_{m2}x_2+\dots+a_{mn}x_n = b_m
\end{cases} ⎩ ⎨ ⎧ a 1 x 1 + a 2 x 2 + ⋯ + a n x n = b 1 a 11 x 1 + a 12 x 2 + ⋯ + a mn x n = b 2 ⋮ a m 1 x 1 + a m 2 x 2 + ⋯ + a mn x n = b m
A solution satisfies all equations.
Solutions:
No solution → parallel lines/planes
One solution → intersection point
Infinite solutions → equations are dependent
Augmented Matrices
Transform system into matrix of coefficients and constants:
{ a 1 x 1 + a 2 x 2 + . . . + a n x n = b 1 a 11 x 1 + a 12 x 2 + . . . + a m n x n = b 2 ↓ a m 1 x 1 + a m 2 x 2 + . . . + a m n x n = b m → Augmented Matrics ( a 1 + a 2 + . . . + a n = b 1 a 11 + a 12 + . . . + a m n = b 2 ↓ a m 1 + a m 2 + . . . + a m n = b m ) \begin{cases}
a_1x_1+a_2x_2+...+a_nx_n& =b_1 \\
a_{11}x_1+a_{12}x_2+...+a_{mn}x_n&=b_2 \\ & \Big\downarrow \\
a_{m1}x_1+a_{m2}x_2+...+a_{mn}x_n&=b_m
\end{cases} \xrightarrow{\text{ Augmented Matrics }}
\begin{pmatrix}
a_1+a_2+...+a_n& =b_1 \\
a_{11}+a_{12}+...+a_{mn}&=b_2 \\ & \Big\downarrow \\
a_{m1}+a_{m2}+...+a_{mn}&=b_m
\end{pmatrix} ⎩ ⎨ ⎧ a 1 x 1 + a 2 x 2 + ... + a n x n a 11 x 1 + a 12 x 2 + ... + a mn x n a m 1 x 1 + a m 2 x 2 + ... + a mn x n = b 1 = b 2 ↓ ⏐ = b m Augmented Matrics a 1 + a 2 + ... + a n a 11 + a 12 + ... + a mn a m 1 + a m 2 + ... + a mn = b 1 = b 2 ↓ ⏐ = b m 1.2 Elementary Row Operations & Row-Reduced Matrices
Elementary Row Operations
Used to simplify matrices for solving:
Only operate by row (not by column).
Matrix example:
( a b c ∣ P d e f ∣ Q g h i ∣ R ) \begin{pmatrix}
\color{violet}a & b & c & | & P \\
\color{violet}d & e & f & | & Q \\
\color{violet}g & h & i & | & R
\end{pmatrix} a d g b e h c f i ∣ ∣ ∣ P Q R
Three operations:
Multiply a row by a constant
R i ← k R i R_i \leftarrow kR_i R i ← k R i Swap two rows
R i ↔ R j R_i \leftrightarrow R_j R i ↔ R j Add a multiple of one row to another
R i ← R i + k R j R_i \leftarrow R_i + kR_j R i ← R i + k R j
Row-Reduced Matrices
Transform into row-echelon or reduced row-echelon form:
Final form (as system):
{ 1 x + 0 + 0 = Δ P 0 + 1 y + 0 = Δ Q 0 + 0 + 1 z = Δ R \begin{cases}
1x + 0 + 0 = \Delta P \\
0 + 1y + 0 = \Delta Q \\
0 + 0 + 1z = \Delta R
\end{cases} ⎩ ⎨ ⎧ 1 x + 0 + 0 = Δ P 0 + 1 y + 0 = Δ Q 0 + 0 + 1 z = Δ R
Final form (as matrix):
( 1 0 0 ∣ Δ P 0 1 0 ∣ Δ Q 0 0 1 ∣ Δ R ) \begin{pmatrix}
1 & 0 & 0 & | & \Delta P \\
0 & 1 & 0 & | & \Delta Q \\
0 & 0 & 1 & | & \Delta R
\end{pmatrix} 1 0 0 0 1 0 0 0 1 ∣ ∣ ∣ Δ P Δ Q Δ R
First nonzero element in each row is 1 (leading 1).
All-zero rows are at the bottom.
Each leading 1 is to the right of any leading 1 above it.
Each leading 1 is the only nonzero entry in its column.
If only 1–3 are satisfied → row-echelon form
If all 1–4 are satisfied → reduced row-echelon form
1.3 Gauss-Jordan Elimination
Used to solve:
{ a x + b y + c z = P d x + e y + f z = Q g x + h y + i z = R ⇒ [ a b c ∣ P d e f ∣ Q g h i ∣ R ] ⇒ [ 1 0 0 ∣ x 0 1 0 ∣ y 0 0 1 ∣ z ] \begin{cases}
ax + by + cz = P \\
dx + ey + fz = Q \\
gx + hy + iz = R
\end{cases}
\Rightarrow
\begin{bmatrix}
a & b & c & | & P \\
d & e & f & | & Q \\
g & h & i & | & R
\end{bmatrix}
\Rightarrow
\begin{bmatrix}
1 & 0 & 0 & | & x \\
0 & 1 & 0 & | & y \\
0 & 0 & 1 & | & z
\end{bmatrix} ⎩ ⎨ ⎧ a x + b y + cz = P d x + ey + f z = Q gx + h y + i z = R ⇒ a d g b e h c f i ∣ ∣ ∣ P Q R ⇒ 1 0 0 0 1 0 0 0 1 ∣ ∣ ∣ x y z
Change one row while keeping the others:
[ a b c ∣ P d e f ∣ Q g h i ∣ R ] → 2 R 1 − R 2 [ Δ a 0 Δ c ∣ Δ P d e f ∣ Q g h i ∣ R ] \begin{bmatrix}
a & b & c & | & P \\
d & e & f & | & Q \\
g & h & i & | & R
\end{bmatrix}
\xrightarrow{2R_1 - R_2}
\begin{bmatrix}
\Delta a & 0 & \Delta c & | & \Delta P \\
d & e & f & | & Q \\
g & h & i & | & R
\end{bmatrix} a d g b e h c f i ∣ ∣ ∣ P Q R 2 R 1 − R 2 Δ a d g 0 e h Δ c f i ∣ ∣ ∣ Δ P Q R
Then scale rows:
[ Δ a 0 0 ∣ Δ P 0 Δ e 0 ∣ Δ Q 0 0 Δ i ∣ Δ R ] ⇒ multiply each by 1 Δ ⇒ [ 1 0 0 ∣ x 0 1 0 ∣ y 0 0 1 ∣ z ] \begin{bmatrix}
\Delta a & 0 & 0 & | & \Delta P \\
0 & \Delta e & 0 & | & \Delta Q \\
0 & 0 & \Delta i & | & \Delta R
\end{bmatrix}
\Rightarrow
\text{multiply each by } \frac{1}{\Delta}
\Rightarrow
\begin{bmatrix}
1 & 0 & 0 & | & x \\
0 & 1 & 0 & | & y \\
0 & 0 & 1 & | & z
\end{bmatrix} Δ a 0 0 0 Δ e 0 0 0 Δ i ∣ ∣ ∣ Δ P Δ Q Δ R ⇒ multiply each by Δ 1 ⇒ 1 0 0 0 1 0 0 0 1 ∣ ∣ ∣ x y z Where:
x = Δ P / Δ a x = \Delta P / \Delta a x = Δ P /Δ a y = Δ Q / Δ e y = \Delta Q / \Delta e y = Δ Q /Δ e z = Δ R / Δ i z = \Delta R / \Delta i z = Δ R /Δ i
Types of Solutions
One solution: intersection point
Infinite solutions: same plane
No solution:
( 1 0 0 ∣ 14 0 1 − 2 ∣ 2 0 0 0 ∣ 1 ) \begin{pmatrix}
1 & 0 & 0 & | & 14 \\
0 & 1 & -2 & | & 2 \\
0 & 0 & 0 & | & 1
\end{pmatrix} 1 0 0 0 1 0 0 − 2 0 ∣ ∣ ∣ 14 2 1
1.4 References
2. Matrix Algebra
2.1 Matrices and Operations
A matrix has m m m n n n m × n m \times n m × n
Column and Row matrices:
n n n row vector m m m column vector
Square matrices
If m = n m = n m = n square matrix
Diagonal matrices
A square matrix where all off-diagonal entries are zero
If the main diagonal has non-zero values, it is called a diagonal matrix
Zero matrices
A matrix where all entries are 0
Identity matrices
A diagonal matrix with all 1s on the diagonal
Denoted by I n I_n I n
2.2 Operations of Matrices
Equality
Two matrices are equal if they have the same size and corresponding entries are equal
Addition
Add corresponding elements; both matrices must have the same size
Scalar Multiplication
Multiply each entry of a matrix A A A k k k k A kA k A
Matrix Multiplication
Only valid if the number of columns of A A A B B B
Not commutative: A B ≠ B A AB \ne BA A B = B A
Power of Square Matrix
For integer n ≥ 0 n \geq 0 n ≥ 0 A 0 = I A^0 = I A 0 = I A n = A ⋅ A ⋅ … ⋅ A A^n = A \cdot A \cdot \ldots \cdot A A n = A ⋅ A ⋅ … ⋅ A
Transpose
Switch rows with columns: A T A^T A T
Tips:
Focus on the columns
When transposing powers: ( A n ) T = ( A T ) n (A^n)^T = (A^T)^n ( A n ) T = ( A T ) n
2.3 Properties of Matrix Operations
A + B = B + A A + B = B + A A + B = B + A A + ( B + C ) = ( A + B ) + C A + (B + C) = (A + B) + C A + ( B + C ) = ( A + B ) + C A ( B C ) = ( A B ) C A(BC) = (AB)C A ( BC ) = ( A B ) C A ( B + C ) = A B + A C A(B + C) = AB + AC A ( B + C ) = A B + A C ( B + C ) A = B A + C A (B + C)A = BA + CA ( B + C ) A = B A + C A A + 0 = 0 + A = A A + 0 = 0 + A = A A + 0 = 0 + A = A A − A = 0 A - A = 0 A − A = 0 0 A = 0 0A = 0 0 A = 0 A 0 = 0 A0 = 0 A 0 = 0 ( A T ) T = A (A^T)^T = A ( A T ) T = A ( A B ) T = B T A T (AB)^T = B^T A^T ( A B ) T = B T A T
2.4 Matrix Inversion
Inverse Matrix
Only square matrices have inverses
For a matrix A A A A A − 1 = I AA^{-1} = I A A − 1 = I A − 1 A^{-1} A − 1
Inverse of a 2 × 2 2 \times 2 2 × 2
If a d − b c ≠ 0 ad - bc \ne 0 a d − b c = 0
( a b c d ) − 1 = 1 a d − b c ( d − b − c a ) \begin{pmatrix}
a & b \\
c & d
\end{pmatrix}^{-1} =
\frac{1}{ad - bc}
\begin{pmatrix}
d & -b \\
-c & a
\end{pmatrix} ( a c b d ) − 1 = a d − b c 1 ( d − c − b a ) Finding Inverse using Gauss-Jordan
Augment matrix A A A I n I_n I n A ∣ I n ⟶ I n ∣ A − 1 A \, | \, I_n \longrightarrow I_n \, | \, A^{-1} A ∣ I n ⟶ I n ∣ A − 1
2.5 Solving Linear System using Inverse
{ a 11 x 1 + a 12 x 2 + ⋯ + a 1 n x n = b 1 a 21 x 1 + a 22 x 2 + ⋯ + a 2 n x n = b 2 ⋮ ⋮ ⋮ ⋮ a m 1 x 1 + a m 2 x 2 + ⋯ + a m n x n = b m ⇒ ( a 11 x 1 + a 12 x 2 + ⋯ + a 1 n x n a 21 x 1 + a 22 x 2 + ⋯ + a 2 n x n ⋮ ⋮ ⋮ a m 1 x 1 + a m 2 x 2 + ⋯ + a m n x n ) = ( b 1 b 2 ⋮ b m ) ⇒ ( a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋮ a m 1 a m 2 ⋯ a m n ) ( x 1 x 2 ⋮ x n ) = ( b 1 b 2 ⋮ b m ) \begin{aligned}
&\left\{
\begin{array}{cccccc}
a_{11}x_1 & + a_{12}x_2 & + \cdots & + a_{1n}x_n &= b_1 \\
a_{21}x_1 & + a_{22}x_2 & + \cdots & + a_{2n}x_n &= b_2 \\
\vdots & \vdots & & \vdots & \vdots \\
a_{m1}x_1 & + a_{m2}x_2 & + \cdots & + a_{mn}x_n &= b_m \\
\end{array}
\right. \\[1em]
\Rightarrow\quad
&\left(
\begin{array}{cccc}
a_{11}x_1 & + a_{12}x_2 & + \cdots & + a_{1n}x_n \\
a_{21}x_1 & + a_{22}x_2 & + \cdots & + a_{2n}x_n \\
\vdots & \vdots & & \vdots \\
a_{m1}x_1 & + a_{m2}x_2 & + \cdots & + a_{mn}x_n \\
\end{array}
\right)
=
\left(
\begin{array}{c}
b_1 \\
b_2 \\
\vdots \\
b_m \\
\end{array}
\right) \\[1em]
\Rightarrow\quad
&\left(
\begin{array}{cccc}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & & \vdots \\
a_{m1} & a_{m2} & \cdots & a_{mn} \\
\end{array}
\right)
\left(
\begin{array}{c}
x_1 \\
x_2 \\
\vdots \\
x_n \\
\end{array}
\right)
=
\left(
\begin{array}{c}
b_1 \\
b_2 \\
\vdots \\
b_m \\
\end{array}
\right)
\end{aligned} ⇒ ⇒ ⎩ ⎨ ⎧ a 11 x 1 a 21 x 1 ⋮ a m 1 x 1 + a 12 x 2 + a 22 x 2 ⋮ + a m 2 x 2 + ⋯ + ⋯ + ⋯ + a 1 n x n + a 2 n x n ⋮ + a mn x n = b 1 = b 2 ⋮ = b m a 11 x 1 a 21 x 1 ⋮ a m 1 x 1 + a 12 x 2 + a 22 x 2 ⋮ + a m 2 x 2 + ⋯ + ⋯ + ⋯ + a 1 n x n + a 2 n x n ⋮ + a mn x n = b 1 b 2 ⋮ b m a 11 a 21 ⋮ a m 1 a 12 a 22 ⋮ a m 2 ⋯ ⋯ ⋯ a 1 n a 2 n ⋮ a mn x 1 x 2 ⋮ x n = b 1 b 2 ⋮ b m 3. Determinants
3.1 Determinants by Cofactor Expansion
3.2 Determinants by Row and Column Reduction
3.3 Cramer's Rule
Solve A X = B AX = B A X = B x i = ∣ A i ∣ ∣ A ∣ , where A i is A with column i replaced by B x_i = \frac{|A_i|}{|A|}, \quad \text{where } A_i \text{ is A with column } i \text{ replaced by } B x i = ∣ A ∣ ∣ A i ∣ , where A i is A with column i replaced by B
Effective only for small systems (2×2 or 3×3)
For n = 2 n = 2 n = 2 n = 3 n = 3 n = 3
3.4 Volume of a Tetrahedron
Given vertices ( x 1 , y 1 , z 1 ) , … , ( x 4 , y 4 , z 4 ) (x_1, y_1, z_1), \dots, (x_4, y_4, z_4) ( x 1 , y 1 , z 1 ) , … , ( x 4 , y 4 , z 4 ) V = ± 1 6 ∣ x 1 y 1 z 1 1 x 2 y 2 z 2 1 x 3 y 3 z 3 1 x 4 y 4 z 4 1 ∣ V = \pm \frac{1}{6} \begin{vmatrix}
x_1 & y_1 & z_1 & 1 \\
x_2 & y_2 & z_2 & 1 \\
x_3 & y_3 & z_3 & 1 \\
x_4 & y_4 & z_4 & 1
\end{vmatrix} V = ± 6 1 x 1 x 2 x 3 x 4 y 1 y 2 y 3 y 4 z 1 z 2 z 3 z 4 1 1 1 1
Always take the positive value of the result as volume
4 - Functions of Several Variables 1
4.1 Introduction, Domains, and Graphs
Domain and Range
Check for square roots, denominators, or other conditions that could lead to undefined expressions.
To find the range , observe the min/max values the expression can take.
4.2 Level Curves and Contour Maps
Level Curves
Level curves are the 2D projections (bird’s-eye view) of surfaces where z = f ( x , y ) z = f(x, y) z = f ( x , y )
Set z = k z = k z = k k k k x x x y y y
Contour Maps
A contour map consists of multiple level curves at different heights z = a , b , c , … z = a, b, c, \dots z = a , b , c , …
Each curve corresponds to the same function value, representing height.
References:
4.3 Partial Derivatives
Concept
For f ( x , y ) f(x,y) f ( x , y )
∂ f ∂ x ⇒ treat y as constant \frac{\partial f}{\partial x} \Rightarrow \text{treat } y \text{ as constant} ∂ x ∂ f ⇒ treat y as constant
∂ f ∂ y ⇒ treat x as constant \frac{\partial f}{\partial y} \Rightarrow \text{treat } x \text{ as constant} ∂ y ∂ f ⇒ treat x as constant
For f ( x , y , z ) f(x, y, z) f ( x , y , z )
Geometrical Interpretation
∂ f ∂ x \displaystyle\frac{\partial f}{\partial x} ∂ x ∂ f z = f ( x , y ) z = f(x, y) z = f ( x , y ) x x x y y y ∂ f ∂ y \displaystyle\frac{\partial f}{\partial y} ∂ y ∂ f z = f ( x , y ) z = f(x, y) z = f ( x , y ) y y y x x x
References:
4.4 Chain Rules
Case 1: Simple Parametric Chain Rule
If z = f ( x , y ) z = f(x, y) z = f ( x , y ) x = g ( t ) , y = h ( t ) x = g(t), y = h(t) x = g ( t ) , y = h ( t )
d z d t = ∂ z ∂ x d x d t + ∂ z ∂ y d y d t \frac{dz}{dt} = \frac{\partial z}{\partial x}\frac{dx}{dt} + \frac{\partial z}{\partial y}\frac{dy}{dt} d t d z = ∂ x ∂ z d t d x + ∂ y ∂ z d t d y Case 2: Multivariable Parametric Chain Rule
If z = f ( x , y ) z = f(x, y) z = f ( x , y ) x = g ( s , t ) , y = h ( s , t ) x = g(s, t), y = h(s, t) x = g ( s , t ) , y = h ( s , t )
∂ z ∂ s = ∂ z ∂ x ∂ x ∂ s + ∂ z ∂ y ∂ y ∂ s \frac{\partial z}{\partial s} = \frac{\partial z}{\partial x}\frac{\partial x}{\partial s} + \frac{\partial z}{\partial y}\frac{\partial y}{\partial s} ∂ s ∂ z = ∂ x ∂ z ∂ s ∂ x + ∂ y ∂ z ∂ s ∂ y
∂ z ∂ t = ∂ z ∂ x ∂ x ∂ t + ∂ z ∂ y ∂ y ∂ t \frac{\partial z}{\partial t} = \frac{\partial z}{\partial x}\frac{\partial x}{\partial t} + \frac{\partial z}{\partial y}\frac{\partial y}{\partial t} ∂ t ∂ z = ∂ x ∂ z ∂ t ∂ x + ∂ y ∂ z ∂ t ∂ y
s , t s, t s , t
x , y x, y x , y
z z z
General Chain Rule for Many Variables
Let w = f ( x , y , z , t , … ) w = f(x, y, z, t, \dots) w = f ( x , y , z , t , … )
5. Functions of Several Variables 2
5.1 Directional Derivatives
Concept
Directional derivative:D u ⃗ f ( x 0 , y 0 ) D_{\vec{u}}f(x_0, y_0) D u f ( x 0 , y 0 ) f f f ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) u ⃗ \vec{u} u
Partial derivatives consider only one direction (x or y), but the directional derivative considers any direction:
D u ⃗ f ( x , y ) = ∇ f ( x , y ) ⋅ u ⃗ = f x ( x , y ) ⋅ a + f y ( x , y ) ⋅ b D_{\vec{u}}f(x, y) = \nabla f(x, y) \cdot \vec{u} = \color{tomato} f_x(x, y) \cdot a + f_y(x, y) \cdot b D u f ( x , y ) = ∇ f ( x , y ) ⋅ u = f x ( x , y ) ⋅ a + f y ( x , y ) ⋅ b Unit Vector
Given vector v v v u ⃗ = v ∣ v ∣ = ⟨ a , b ⟩ \vec{u} = \frac{v}{|v|} = \langle a, b \rangle u = ∣ v ∣ v = ⟨ a , b ⟩
Given an angle θ \theta θ
a = cos θ a = \cos \theta a = cos θ b = sin θ b = \sin \theta b = sin θ Since ∣ u ⃗ ∣ = 1 |\vec{u}| = 1 ∣ u ∣ = 1 u ⃗ = ⟨ cos θ , sin θ ⟩ \vec{u} = \langle \cos \theta, \sin \theta \rangle u = ⟨ cos θ , sin θ ⟩
5.2 Gradient Vector
Gradient Definition
The gradient vector ∇ f ( x , y , z ) \nabla f(x, y, z) ∇ f ( x , y , z )
∇ f ( x , y , z ) = ⟨ f x , f y , f z ⟩ = ∂ f ∂ x i + ∂ f ∂ y j + ∂ f ∂ z k \nabla f(x, y, z) = \left\langle f_x, f_y, f_z \right\rangle = \frac{\partial f}{\partial x} \, \mathbf{i} + \frac{\partial f}{\partial y} \, \mathbf{j} + \frac{\partial f}{\partial z} \, \mathbf{k} ∇ f ( x , y , z ) = ⟨ f x , f y , f z ⟩ = ∂ x ∂ f i + ∂ y ∂ f j + ∂ z ∂ f k
It is the vector sum of all partial derivatives, pointing in the direction of steepest increase.
5.3 Tangent Planes
Equation of Plane
Let p ( x 0 , y 0 , z 0 ) p(x_0, y_0, z_0) p ( x 0 , y 0 , z 0 )
General form (based on gradient and point):
z = a ( x − x 0 ) + b ( y − y 0 ) + z 0 z = a(x - x_0) + b(y - y_0) + z_0 z = a ( x − x 0 ) + b ( y − y 0 ) + z 0
Since a = f x ( x 0 , y 0 ) a = f_x(x_0, y_0) a = f x ( x 0 , y 0 ) b = f y ( x 0 , y 0 ) b = f_y(x_0, y_0) b = f y ( x 0 , y 0 )
P ( x , y ) = f x ( x 0 , y 0 ) ( x − x 0 ) + f y ( x 0 , y 0 ) ( y − y 0 ) + f ( x 0 , y 0 ) \color{tomato}
P(x, y) = f_x(x_0, y_0)(x - x_0) + f_y(x_0, y_0)(y - y_0) + f(x_0, y_0) P ( x , y ) = f x ( x 0 , y 0 ) ( x − x 0 ) + f y ( x 0 , y 0 ) ( y − y 0 ) + f ( x 0 , y 0 ) Derivative with Respect to Each Variable
Let P ( x , y ) P(x, y) P ( x , y )
Partial with respect to x x x
P x ( x , y ) = a ⇒ P x ( x 0 , y 0 ) = a = f x ( x 0 , y 0 ) P_x(x, y) = a \quad \Rightarrow \quad P_x(x_0, y_0) = a = \color{tomato} f_x(x_0, y_0) P x ( x , y ) = a ⇒ P x ( x 0 , y 0 ) = a = f x ( x 0 , y 0 )
Partial with respect to y y y
P y ( x , y ) = b ⇒ P y ( x 0 , y 0 ) = b = f y ( x 0 , y 0 ) P_y(x, y) = b \quad \Rightarrow \quad P_y(x_0, y_0) = b = \color{tomato} f_y(x_0, y_0) P y ( x , y ) = b ⇒ P y ( x 0 , y 0 ) = b = f y ( x 0 , y 0 ) 5.4 Analogy to 1D Tangent Lines
For 1D function f ( x ) f(x) f ( x )
{ L ( x 0 ) = f ( x 0 ) L ′ ( x 0 ) = f ′ ( x 0 ) \begin{cases}
L(x_0) = f(x_0) \\
L'(x_0) = f'(x_0)
\end{cases} { L ( x 0 ) = f ( x 0 ) L ′ ( x 0 ) = f ′ ( x 0 )
For 2D surface f ( x , y ) f(x, y) f ( x , y ) P ( x , y ) P(x, y) P ( x , y )
{ P ( x 0 , y 0 ) = f ( x 0 , y 0 ) { P x ( x 0 , y 0 ) = f x ( x 0 , y 0 ) P y ( x 0 , y 0 ) = f y ( x 0 , y 0 ) \begin{cases}
P(x_0, y_0) = f(x_0, y_0) \\
\begin{cases}
P_x(x_0, y_0) = f_x(x_0, y_0) \\
P_y(x_0, y_0) = f_y(x_0, y_0)
\end{cases}
\end{cases} ⎩ ⎨ ⎧ P ( x 0 , y 0 ) = f ( x 0 , y 0 ) { P x ( x 0 , y 0 ) = f x ( x 0 , y 0 ) P y ( x 0 , y 0 ) = f y ( x 0 , y 0 ) References
Week 6 - Double Integrals 1
6.1 Double Integrals over General Regions
Concept
When the shape is not a rectangle, use directional slicing (horizontal or vertical).
If two bounding curves are given, find the intercept points between them first to determine the limits of integration.
Points of intersection will define:
x x x x ∈ [ a , b ] x \in [a, b] x ∈ [ a , b ] y y y y ∈ [ c , d ] y \in [c, d] y ∈ [ c , d ]
Choosing the Order of Integration
You may integrate with respect to y y y x x x
Example:
If integrating in y y y V = ∫ a b ∫ g 1 ( x ) g 2 ( x ) f ( x , y ) d y d x V = \int_a^b \int_{g_1(x)}^{g_2(x)} f(x, y) \, dy \, dx V = ∫ a b ∫ g 1 ( x ) g 2 ( x ) f ( x , y ) d y d x
If integrating in x x x V = ∫ c d ∫ h 1 ( y ) h 2 ( y ) f ( x , y ) d x d y V = \int_c^d \int_{h_1(y)}^{h_2(y)} f(x, y) \, dx \, dy V = ∫ c d ∫ h 1 ( y ) h 2 ( y ) f ( x , y ) d x d y
References
6.2 Reversing the Order of Integration
Concept
Used when the current order of integration is hard to compute.
Unlike double integrals over rectangles (with constant bounds), these often have variable bounds.
You can switch from d y → d x dy \to dx d y → d x
Strip Visualization
Vertical Strip (dy first): fix x x x y y y Horizontal Strip (dx first): fix y y y x x x
Rewriting Limits
Given:
∫ c d ∫ g ( x ) b f ( x , y ) d y d x \int_c^d \int_{g(x)}^b f(x, y) \, dy \, dx ∫ c d ∫ g ( x ) b f ( x , y ) d y d x
First analyze the bounds:
x ∈ [ c , d ] x \in [c, d] x ∈ [ c , d ] y ∈ [ g ( x ) , b ] y \in [g(x), b] y ∈ [ g ( x ) , b ]
Sketch the region: include x = c x = c x = c x = d x = d x = d y = g ( x ) y = g(x) y = g ( x ) y = b y = b y = b
Then reverse the order:
∫ m l ∫ k h ( y ) f ( x , y ) d x d y \int_m^l \int_k^{h(y)} f(x, y) \, dx \, dy ∫ m l ∫ k h ( y ) f ( x , y ) d x d y
New bounds are derived from the region in the graph.
References
Mathematic 2 - Statistic - Summary
1. Introduction to Statistics
1.1 Introduction to Statistics & Classification of Data
Concept
Definition of statistical methods:
Population : Statistic from the whole population (not practical).
Parameter : Summarizes data from a population.
Sample : Statistic from a subset (more feasible).
Statistic : Summarizes data from a sample.
Simple random sample : Considers all people equally.
Accuracy check for sample:
∣ sample average − population average ∣ ≤ n |\text{sample average} - \text{population average}| \leq n ∣ sample average − population average ∣ ≤ n
Big difference: inaccurate
Small difference: accurate
Confidence interval : Interval where the true value is likely to lie.
Types of Data
Qualitative Nominal : Categorical, no order (e.g., Gender, State).Qualitative Ordinal : Categorical with order (e.g., Grades, Survey responses).Quantitative Discrete : Numeric, countable (e.g., Number of cars).Quantitative Continuous : Numeric, measurable (e.g., Exam time, Resistance).
1.2 Frequency Distribution & Histograms
Frequency Distribution
Used to handle large amounts of data by grouping into classes.
Classes must be non-overlapping and contain all data .
Frequency Distribution Table
Class Interval Frequency Relative Frequency 83 ≤ x < 85 3 0.04 85 ≤ x < 87 4 0.05 87 ≤ x < 89 17 0.21 89 ≤ x < 91 23 0.28 91 ≤ x < 93 21 0.26 93 ≤ x < 95 10 0.12 95 ≤ x < 97 2 0.02 97 ≤ x < 99 1 0.01 99 ≤ x < 101 1 0.01 Total 82 1.00 \begin{array}{|c|c|c|}
\hline
\textbf{Class Interval} & \textbf{Frequency} & \textbf{Relative Frequency} \\
\hline
83 \leq x < 85 & 3 & 0.04 \\
85 \leq x < 87 & 4 & 0.05 \\
87 \leq x < 89 & 17 & 0.21 \\
89 \leq x < 91 & 23 & 0.28 \\
91 \leq x < 93 & 21 & 0.26 \\
93 \leq x < 95 & 10 & 0.12 \\
95 \leq x < 97 & 2 & 0.02 \\
97 \leq x < 99 & 1 & 0.01 \\
99 \leq x < 101 & 1 & 0.01 \\
\hline
\textbf{Total} & \textbf{82} & \textbf{1.00} \\
\hline
\end{array} Class Interval 83 ≤ x < 85 85 ≤ x < 87 87 ≤ x < 89 89 ≤ x < 91 91 ≤ x < 93 93 ≤ x < 95 95 ≤ x < 97 97 ≤ x < 99 99 ≤ x < 101 Total Frequency 3 4 17 23 21 10 2 1 1 82 Relative Frequency 0.04 0.05 0.21 0.28 0.26 0.12 0.02 0.01 0.01 1.00 Histogram
Visual bar graph based on class intervals and frequencies.
X-axis: Class intervals
Y-axis: Frequency
Bar height = frequency
2. Descriptive Statistics
2.1 Measures of Central Tendency
Mean
X ‾ = ∑ X n n = ∑ x f f \overline{X}= \frac{\sum X_n}{n} = \frac{\sum xf}{f} X = n ∑ X n = f ∑ x f
The middle value, or average of the two middle values, in an ordered dataset.
Mode
The value that appears most frequently in the data.
Modal class : the class interval with the highest frequency density.
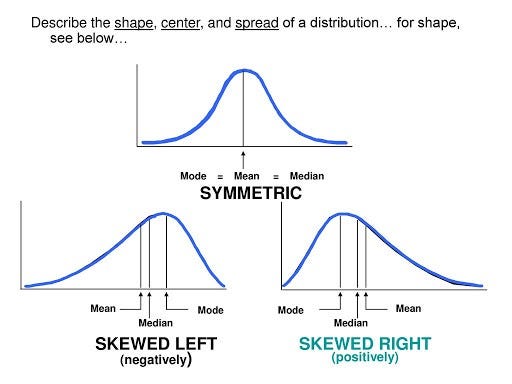
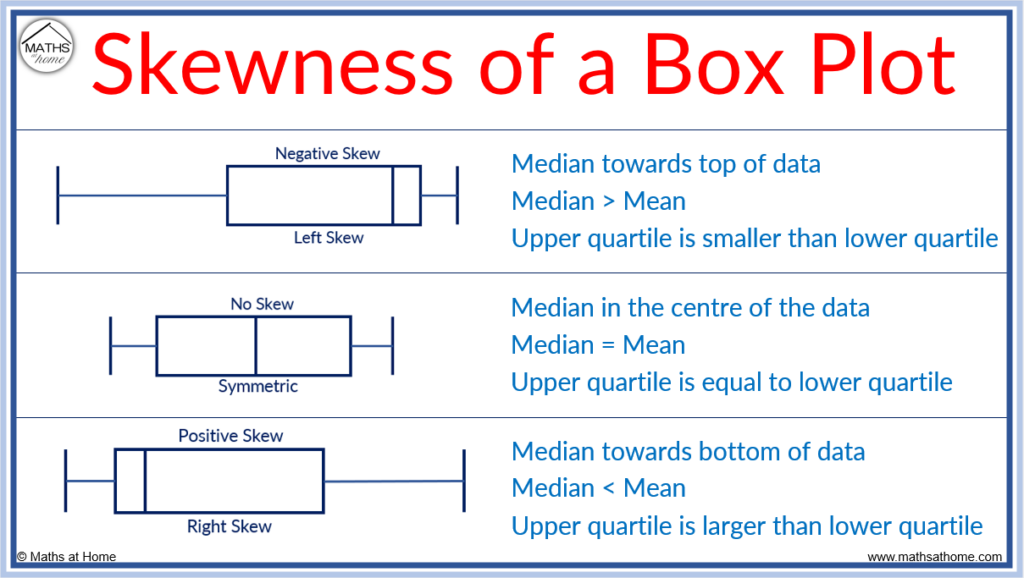
Skewness
Symmetric : Mode = Median = MeanPositively skewed : Mean > Median > ModeNegatively skewed : Mean < Median < Mode
2.2 Measures of Dispersion
[[Range, Variance, Standard Deviation, The Coefficient of Variation]]
[[The Interquartile Range, A Box-and-Whisker Plot]]
Range
Range = x max − x min \text{Range} = x_{\text{max}} - x_{\text{min}} Range = x max − x min
Variance and Standard Deviation
Sample Variance s 2 = ∑ ( x − x ˉ ) 2 n − 1 = ∑ x 2 − ( ∑ x ) 2 n n − 1 s^2 = \frac{\sum (x - \bar{x})^2}{n - 1} = \frac{\sum x^2 - \frac{(\sum x)^2}{n}}{n - 1} s 2 = n − 1 ∑ ( x − x ˉ ) 2 = n − 1 ∑ x 2 − n ( ∑ x ) 2
Sample Standard Deviation s = s 2 s = \sqrt{s^2} s = s 2
Coefficient of Variation
A normalized measure of dispersion:CV = s x ˉ × 100 \text{CV} = \frac{s}{\bar{x}} \times 100 CV = x ˉ s × 100
Interquartile Range (IQR)
x_min ─── Q₁ ─── Q₂ (Median) ─── Q₃ ─── x_max 25% 25% 25% 25% I Q R = Q 3 − Q 1 IQR = Q_3 - Q_1 I QR = Q 3 − Q 1
Box-and-Whisker Plot
Box plot includes: min, max, lower quartile (Q1), median (Q2), upper quartile (Q3).
Whiskers :
Lower whisker: larger of lower limit or minimum value.
Upper whisker: smaller of upper limit or maximum value.
3. Basic Probability
3.1 Sample Space & Events
Concepts
Sample Space (S S S : Set of all possible outcomes of the experiment.
Event (E E E : A subset of S S S Complement of Event E E E E ‾ \overline{E} E E c E^c E c : Event not in E E E P ( E ‾ ) = 1 − P ( E ) P(\overline{E}) = 1 - P(E) P ( E ) = 1 − P ( E )
AND, OR
AND (E ∩ F E \cap F E ∩ F : Both E E E F F F OR (E ∪ F E \cup F E ∪ F : E E E F F F
Mutually Exclusive and Subset
Mutually Exclusive : E ∩ F = ∅ E \cap F = \emptyset E ∩ F = ∅ Subset : E ⊆ F E \subseteq F E ⊆ F
Axioms of Probability
0 ≤ P ( E ) ≤ 1 0 \leq P(E) \leq 1 0 ≤ P ( E ) ≤ 1 P ( S ) = 1 P(S) = 1 P ( S ) = 1 For mutually exclusive events:
P ( E 1 ∪ E 2 ∪ . . . ∪ E n ) = P ( E 1 ) + P ( E 2 ) + . . . + P ( E n ) P(E_1 \cup E_2 \cup ... \cup E_n) = P(E_1) + P(E_2) + ... + P(E_n) P ( E 1 ∪ E 2 ∪ ... ∪ E n ) = P ( E 1 ) + P ( E 2 ) + ... + P ( E n )
Algebra of Events
Complement Rule :
P ( E ‾ ) = 1 − P ( E ) P(\overline{E}) = 1 - P(E) P ( E ) = 1 − P ( E ) Addition Rule :
P ( E ∪ F ) = P ( E ) + P ( F ) − P ( E ∩ F ) P(E \cup F) = P(E) + P(F) - P(E \cap F) P ( E ∪ F ) = P ( E ) + P ( F ) − P ( E ∩ F )
Extended Concepts
Mutually Exclusive : Cannot occur together (e.g., coin toss: head or tail)Independent : One does not affect the other (e.g., YouTube like and share)
Probability of A A A B B B
P ( A and B ‾ ) = P ( A ) − P ( A ∩ B ) P(A \text{ and } \overline{B}) = P(A) - P(A \cap B) P ( A and B ) = P ( A ) − P ( A ∩ B )
3.2 Conditional Probability
Conditional probability:
P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A | B) = \frac{P(A \cap B)}{P(B)} P ( A ∣ B ) = P ( B ) P ( A ∩ B )
Total Probability Rule
If B 1 , B 2 , . . . , B n B_1, B_2, ..., B_n B 1 , B 2 , ... , B n P ( A ) = ∑ i = 1 n P ( A ∣ B i ) P ( B i ) P(A) = \sum_{i=1}^{n} P(A|B_i)P(B_i) P ( A ) = i = 1 ∑ n P ( A ∣ B i ) P ( B i )
3.3 Independent Events
E E E F F F P ( E ∩ F ) = P ( E ) P ( F ) P(E \cap F) = P(E)P(F) P ( E ∩ F ) = P ( E ) P ( F ) Check independence:
P ( E ) = P ( E ∣ F ) ⟺ P ( E ∩ F ) = P ( E ) P ( F ) P(E) = P(E|F) \iff P(E \cap F) = P(E)P(F) P ( E ) = P ( E ∣ F ) ⟺ P ( E ∩ F ) = P ( E ) P ( F )
Independent ≠ Mutually Exclusive
3.4 Bayes' Theorem
Formula:
P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} P ( A ∣ B ) = P ( B ) P ( B ∣ A ) ⋅ P ( A )
Reference
4. Discrete Random Variables
4.1 Introduction to Random Variables
Concept
Sample Space (S) : Set of all possible outcomes of a statistical experiment.Element/Sample point : Each outcome that belongs to the sample space.Random Variable : A function applied to sample space and its elements to generate a range of values used for probability calculation.
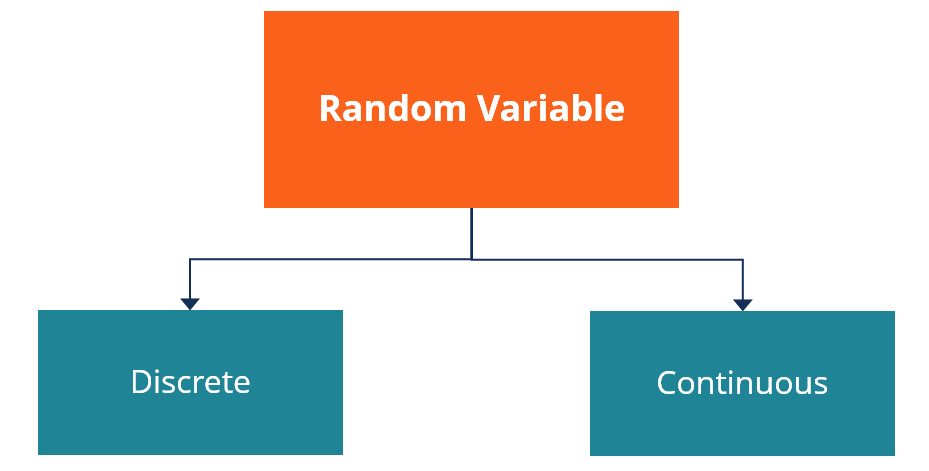
4.2 Discrete and Continuous Random Variables
Concept
Discrete Sample Space : Countable outcomes.
Discrete Random Variable : A random variable defined over a discrete sample space.
Continuous Sample Space : Uncountable outcomes.
Continuous Random Variable : A random variable defined over a continuous sample space.
4.3 The Binomial and Poisson Distributions
Binomial Distribution
Conditions
Experiment consists of n n n
Each trial has two possible outcomes (success/failure).
Probability of success p p p
Trials are independent.
Distribution
X ∼ B ( n , p ) X \sim B(n, p) X ∼ B ( n , p )
Formula:P r = ( n r ) p r q n − r P_r = \binom{n}{r} p^r q^{n-r} P r = ( r n ) p r q n − r q = 1 − p q = 1 - p q = 1 − p
Expected Value :E ( X ) = n ⋅ p E(X) = n \cdot p E ( X ) = n ⋅ p
Variance :V a r ( X ) = σ 2 = n ⋅ p ⋅ q Var(X) = \sigma^2 = n \cdot p \cdot q Va r ( X ) = σ 2 = n ⋅ p ⋅ q
Poisson Distribution
Conditions
Describes number of events over an interval (time, area, volume).
Occurrences happen:
Randomly
Independently
At a constant average rate
Distribution
X ∼ P o ( λ ) X \sim Po(\lambda) X ∼ P o ( λ )
Formula:P ( X = x ) = e − λ λ x x ! , λ > 0 P(X = x) = \frac{e^{-\lambda} \lambda^x}{x!}, \quad \lambda > 0 P ( X = x ) = x ! e − λ λ x , λ > 0
Expected Value and Variance :E ( X ) = μ = λ , V a r ( X ) = λ E(X) = \mu = \lambda, \quad Var(X) = \lambda E ( X ) = μ = λ , Va r ( X ) = λ
Probability of r r r :P ( X = r ) = e − λ λ r r ! P(X = r) = \frac{e^{-\lambda} \lambda^r}{r!} P ( X = r ) = r ! e − λ λ r E ( X = r ) = n ⋅ P ( X = r ) E(X = r) = n \cdot P(X = r) E ( X = r ) = n ⋅ P ( X = r )
Notes:
Discrete values
No upper bound
Mean and variance are approximately equal